Descripción del proyecto
El stack de monitorización nació de la necesidad de saber en todo momento el estado real del homelab sin tener que conectarse manualmente a los servidores. El objetivo era claro: si algo falla o se acerca a un límite crítico, recibir una notificación inmediatamente en el móvil.
El pipeline completo funciona así: Prometheus recopila métricas de ambos nodos cada 15 segundos via Node Exporter. Grafana visualiza esas métricas en dashboards en tiempo real. Cuando una métrica supera un umbral configurado, Grafana dispara una alerta hacia n8n via webhook. n8n procesa la alerta, la formatea y la envía a ntfy, que a su vez la reenvía como push notification a Telegram.
Pipeline de alertas
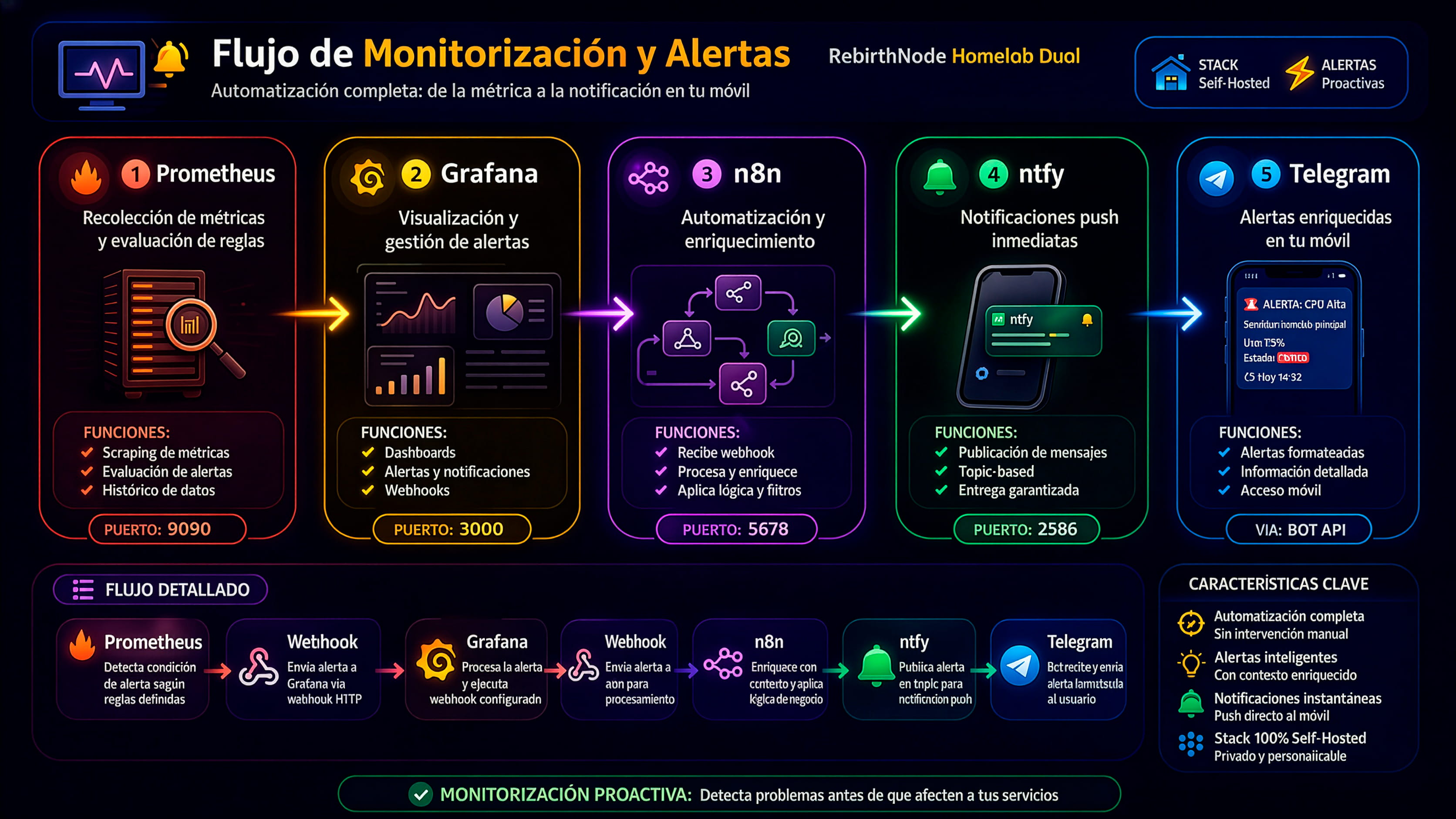
- Prometheus scrape cada 15s desde Node Exporter en ambos nodos
- 9 reglas de alerta: CPU >85%, RAM >90%, disco >80%, servicio down
- Grafana Unified Alerting con estado pending/firing/resolved
- n8n workflow recibe webhook de Grafana y formatea el mensaje
- ntfy como broker push notification, delivery garantizado
- Mensajes Telegram con formato Markdown: emoji + métricas + timestamp
- Resolución automática: notificación cuando la alerta se resuelve
Configuración Prometheus
Configuración simplificada de prometheus.yml con los dos nodos del homelab y cAdvisor:
global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'node-homelabES' static_configs: - targets: ['100.x.x.x:9100'] labels: instance: 'homelabES' - job_name: 'node-hlia' static_configs: - targets: ['100.x.x.x:9100'] labels: instance: 'hlia' - job_name: 'cadvisor' static_configs: - targets: ['localhost:8080']
Capturas de pantalla
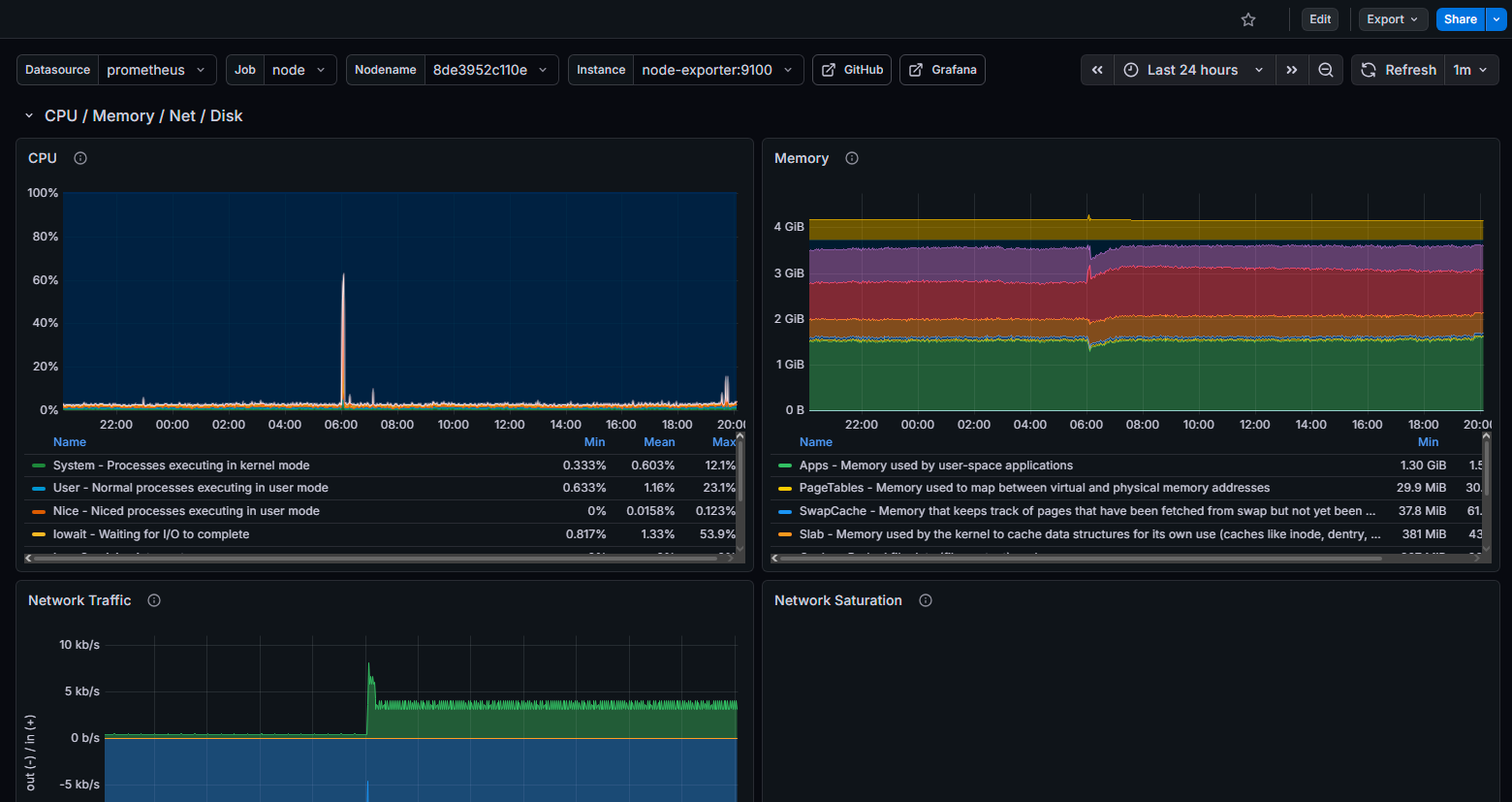
Dashboard Grafana
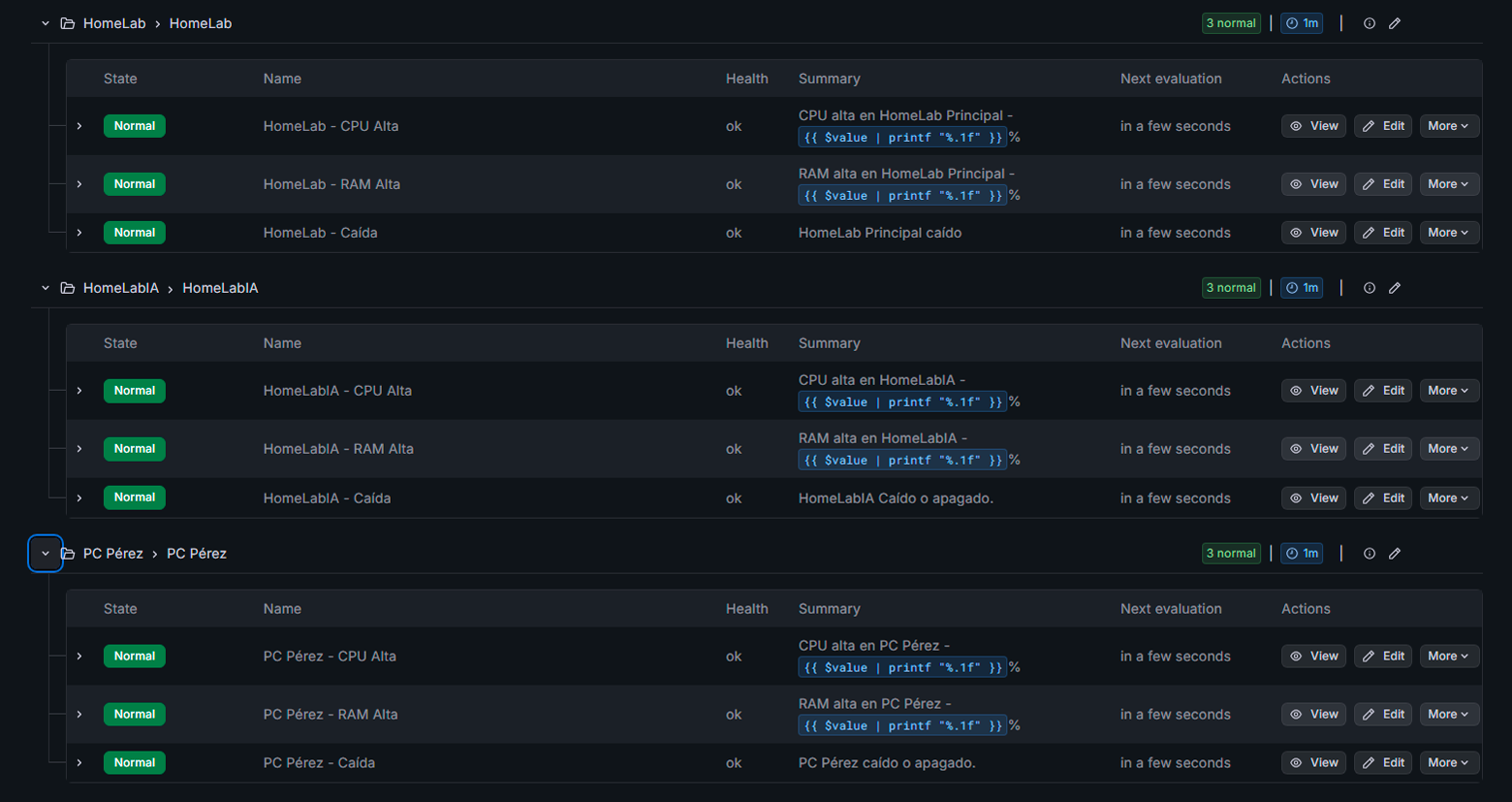
Alertas Grafana
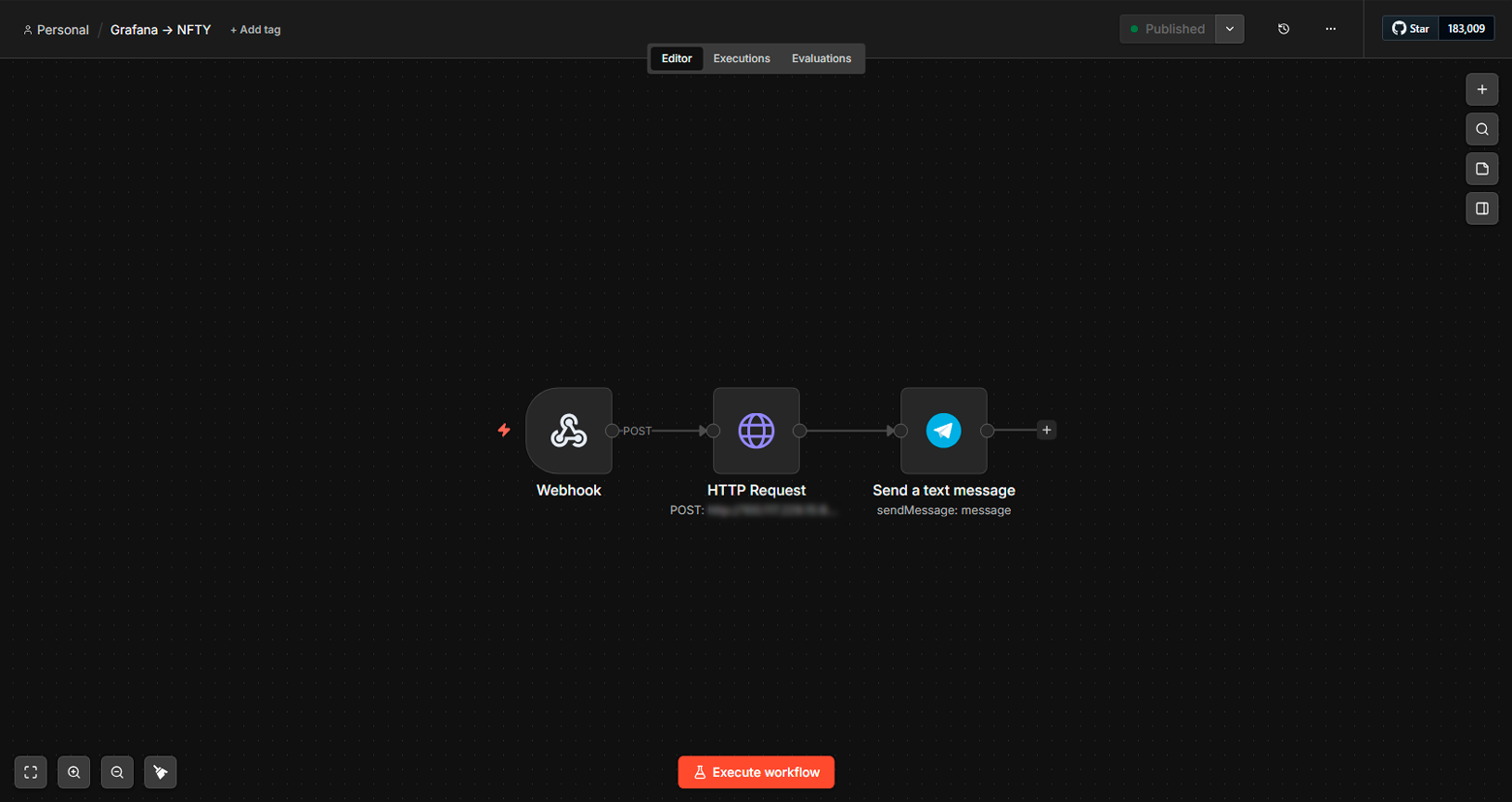
Workflow n8n
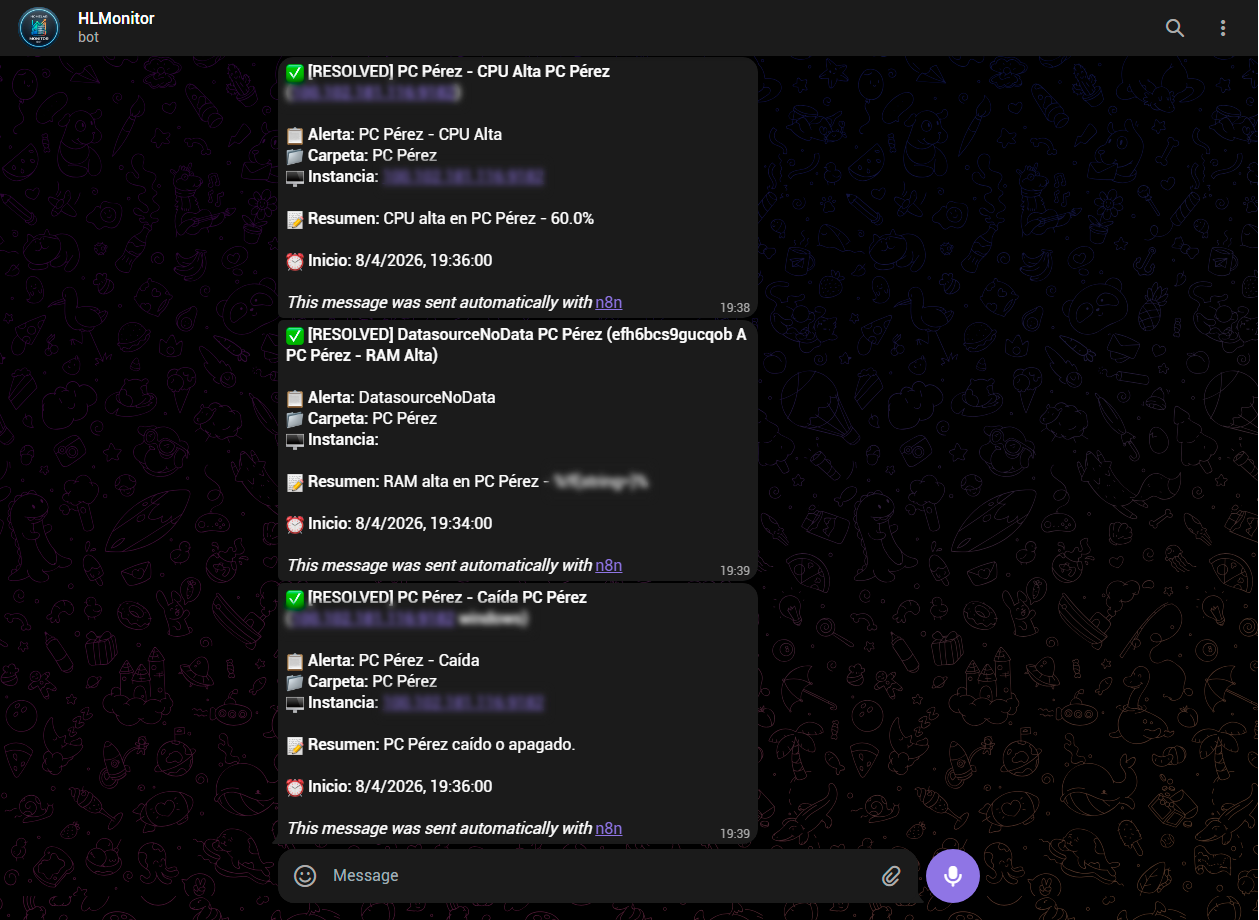
Bot Telegram
Retos y soluciones
- Alertas duplicadas en n8n: Grafana envía el mismo estado varias veces durante pending → resuelto con un nodo IF en n8n que filtra por estado firing/resolved exclusivamente.
- Emojis en headers HTTP: n8n violaba RFC al poner emojis en nombres de workflow; resuelto sanitizando los nombres y moviendo emojis al cuerpo del mensaje.
- Conectividad Tailscale en compose: Node Exporter necesitaba la IP de Tailscale del nodo remoto, que cambia; resuelto usando los hostnames estables de Tailscale MagicDNS.
- Grafana volumen persistente: permisos de directorio fallaban en Docker; solucionado con
user: "472"en el compose.
Aprendizajes
Este proyecto me dio una comprensión profunda de cómo funciona la observabilidad a nivel de sistema. Entender Prometheus desde cero — el modelo pull, los label sets, las PromQL queries — fue especialmente valioso.
La parte de n8n me enseñó a construir pipelines de automatización robustos: cómo manejar errores, reintentos y estados, y cómo transformar datos entre diferentes formatos y APIs.